
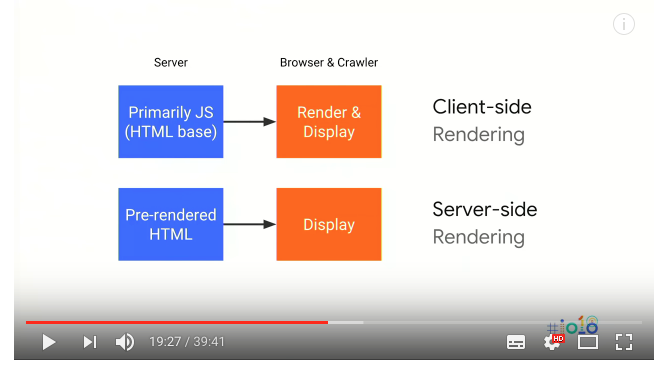
這是 Google I/O 2018 的影片的一些摘要、心得,建議是直接看影片是比較快拉~XD Deliver search-friendly JavaScript-powered websites (Google I/O ’18) 這個前端程式詮釋網站內容導致 SEO 問題其實也討論很久了,前陣子 …
標籤彙整: Crawler
[筆記] 沒有 API 也能自造的暴力做法:爬蟲 Crawler

說實在會搞到要寫爬蟲也是下下策,不是個方便的解法。對於用法我就不多做介紹了,工具玩法不是筆記中要傳達的~ (等等被說教壞人怎辦!?XD) 平時要寫爬蟲時,會先使用 CURL 命令列工具測試一次: curl -b cookie -c cookie https://www.mxp.tw/login -d …
[轉貼] Headless Chrome 使用 Puppeteer NodeJS API 實作爬蟲

剛看到這篇「A Guide to Automating & Scraping the Web with JavaScript (Chrome + Puppeteer + Node JS)」爬蟲實作指南,寫得很詳細,值得收藏筆記一下! 透過 Puppeteer 這套件能將瀏覽器行為程式模組化, …
[PHP] CURL 跟隨301、302轉址實現 Google 雲端硬碟檔案下載

這個題目在寫爬蟲的時候算滿常見會要解決的問題。 正好這次因為要爬的對象把資料改放到 Google 雲端硬碟上,所以就來紀錄一下這段程式吧! 是說指令版的 curl 實在是超好物,一跨到程式上就麻煩不少了XD <?php //Ref: http://php.net/manual/en/ref.c …