
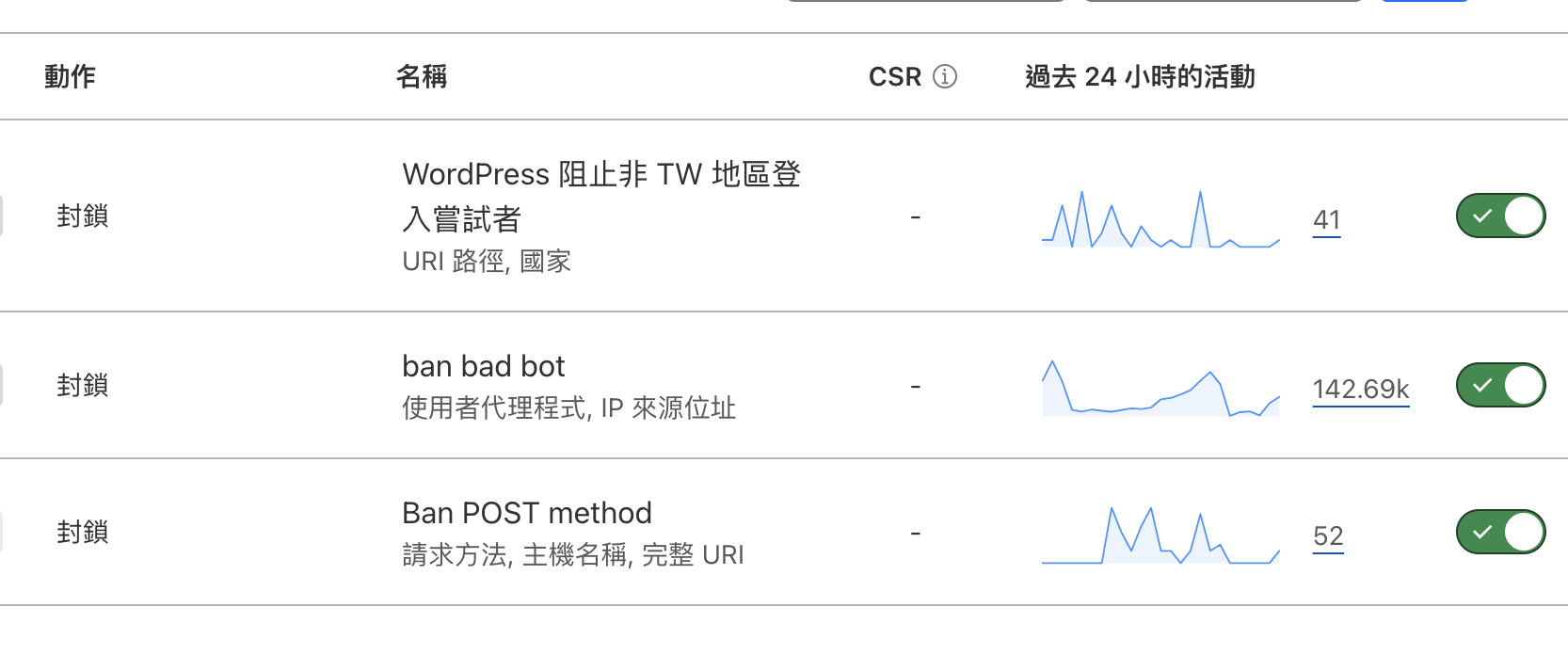
昨天網站開始大量收到一組來自中國 IP 的請求,請求時間都很短,實屬惡意爬蟲的砍站行為。 收到警示通知後就把那整組 IP 丟給 Cloudflare WAF 防火牆功能給設定封鎖。 直到今天都還在很努力地爬,完全沒發現自己已經被封鎖了。 更多類似的資安防護操作筆記可以參考: [Fail2ban] 同 …
標籤彙整: 爬蟲
[WordPress] 外掛庫分析統計資訊(截至 2022/08/27)
![[WordPress] 外掛庫分析統計資訊(截至 2022/08/27)](https://www.mxp.tw/wp-content/uploads/2022/08/9457-cover.webp)
最近寫了個爬蟲,把 WordPress 外掛庫爬完後,統計資訊如下: 外掛庫總數:96293 筆 還在架上的:59041 筆 還在架上,但沒有 readme.txt 宣告檔案的: 6799 筆 不在架上,也沒有 readme.txt 宣告檔案的: 14437 筆 啟用安裝數大於一百萬的外掛 Slug …
[Nginx] 阻擋惡意請求來源(User-Agent)的方法
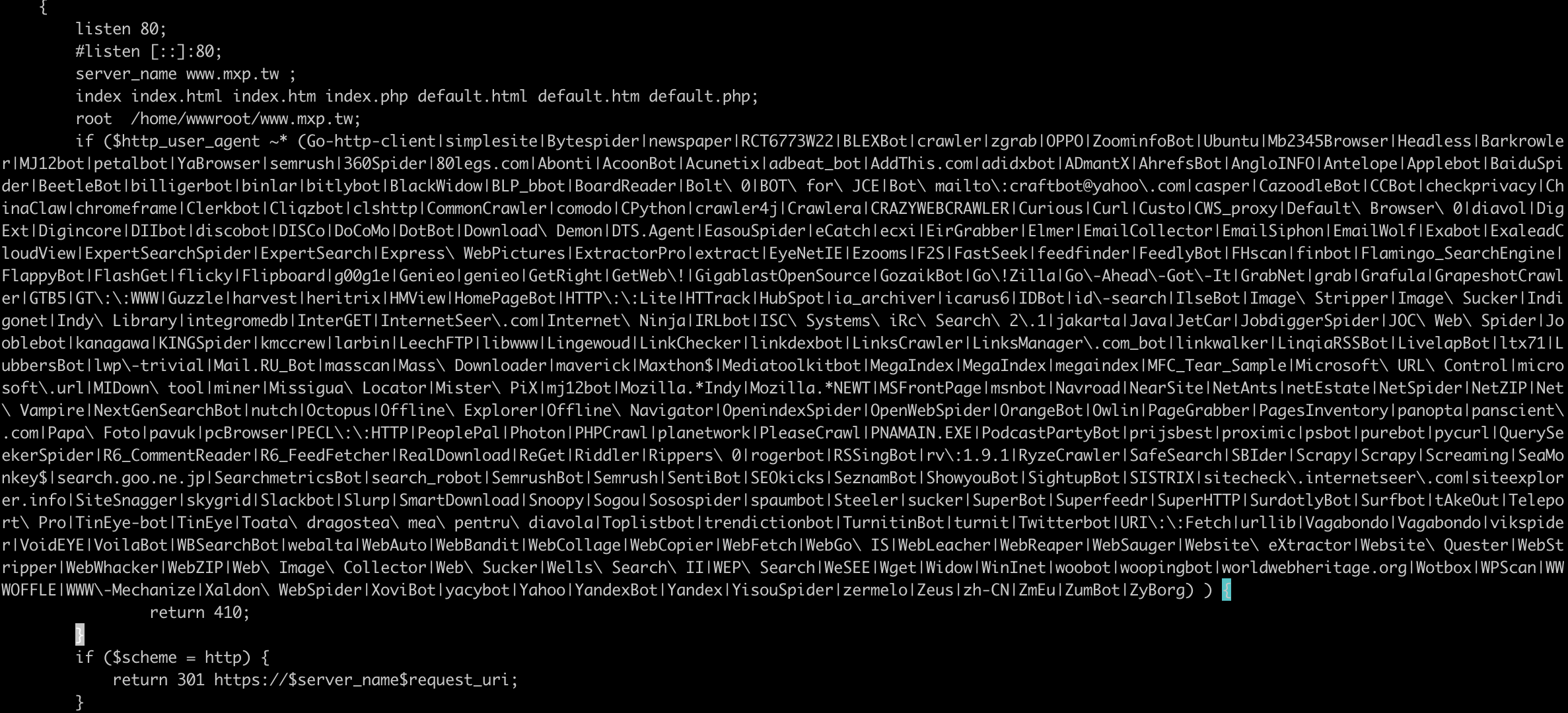
現在只要一開站,就有無數的「機器人(爬蟲、Bot)」來光臨,而一個內容網站機器人通常應該要比真人瀏覽來得少,如果這比例失衡,滿有可能「網站正在被攻擊」。 面對這種「可能的」攻擊,就要做出防範,以免問題擴大。 後果: 因為太多機器人請求網站,導致網站主機資源不足,停止服務(DDoS攻擊)。 網站已經有 …
[PHP] 不用 Instagram API 取得照片列表的方法(爬蟲)
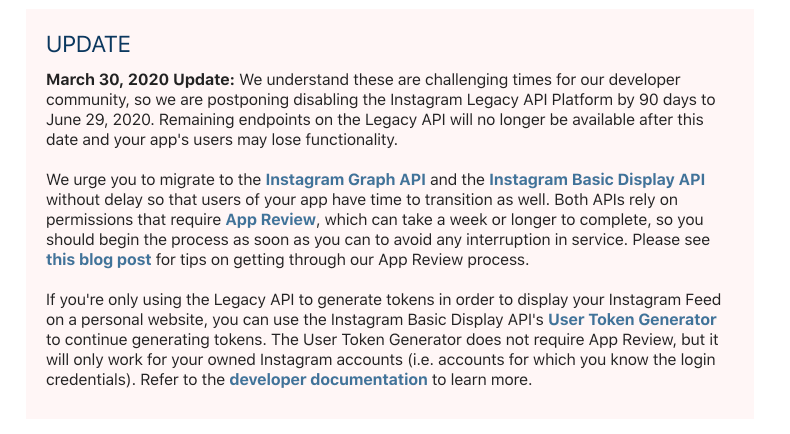
有鑒於 Instagram 發了個公告,表示 2020/06/29 後就要取消所有舊版本 API 存取,都移轉至 Facebook Graph API 的方式整合進 Facebook 中。 Instagram 其實 2019 年就已先公告過,所以近期很多 WordPress 裡原本使用好好的方法都開 …
[AMP] 零開發零負擔的 AMP 頁面產生方式
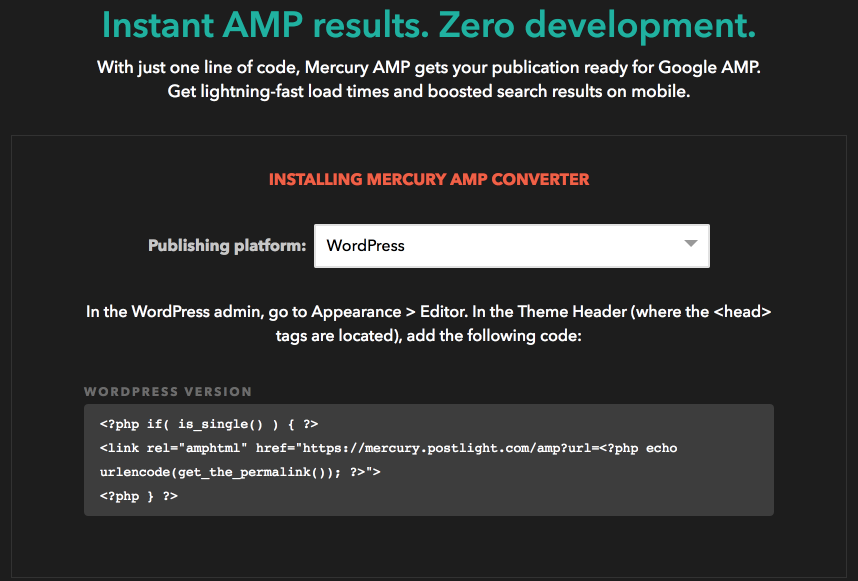
是 Postlight 這家公司的一個爬蟲解析應用之一。 AMP Converter 這隻爬蟲程式前陣子開源了:Mercury Web Parser 很強大~ 回到這個 AMP 轉換方式也好有創意,畢竟本來就沒說一定要同一個網域來吐 AMP 資料,過這個 API 方法先把網站內容分析完後再轉為 AM …
[Crawler] Google 與 Facebook 爬蟲觀察進度 – 它會叫了!(誤)

標題浮誇請忽略,主要是這兩邊蟲子最近都有人有新觀察。國外這篇文章「Googlebot’s Javascript random() function is deterministic」,作者觀察到 Google 爬蟲執行 JavaScript 有一個自己的「道理」,這塊有興趣自己看文章便知一二,而我的 …
[筆記] 沒有 API 也能自造的暴力做法:爬蟲 Crawler

說實在會搞到要寫爬蟲也是下下策,不是個方便的解法。對於用法我就不多做介紹了,工具玩法不是筆記中要傳達的~ (等等被說教壞人怎辦!?XD) 平時要寫爬蟲時,會先使用 CURL 命令列工具測試一次: curl -b cookie -c cookie https://www.mxp.tw/login -d …
[轉貼] Headless Chrome 使用 Puppeteer NodeJS API 實作爬蟲

剛看到這篇「A Guide to Automating & Scraping the Web with JavaScript (Chrome + Puppeteer + Node JS)」爬蟲實作指南,寫得很詳細,值得收藏筆記一下! 透過 Puppeteer 這套件能將瀏覽器行為程式模組化, …
[PHP] 使用正規表示法(RegEx)解析 HTML 文件時,移除特殊字元的陷阱
這幾天都在用 NodeJS 寫爬蟲去測試解析資料,然後昨天要改用 PHP 實作的時候就發生一個詭異問題: 抽出來的文件是正常,但一經過移除斷行的解析時,整個文件編碼就走山了! preg_replace(‘/s+/’, ‘ ‘, $content); 怎麼想都是 preg_replace 這方法幫我加 …
[PHP] CURL 跟隨301、302轉址實現 Google 雲端硬碟檔案下載

這個題目在寫爬蟲的時候算滿常見會要解決的問題。 正好這次因為要爬的對象把資料改放到 Google 雲端硬碟上,所以就來紀錄一下這段程式吧! 是說指令版的 curl 實在是超好物,一跨到程式上就麻煩不少了XD <?php //Ref: http://php.net/manual/en/ref.c …